
東京大学教養学部
全学ゼミ「インターネットテクノロジー入門」
講義ノート (1998年1月9日)
豊田英司
toyoda@ms.u-tokyo.ac.jp
東京大学大学院数理科学研究科
計算機が文字を扱うときは、文字を整数に対応させて表現していることが多い。 この文字と対応する整数 (あるいは対応づけ) を 文字コード(character code) という。
インターネットなどで英語や日本語のローマ字表記を使うならば 文字コードについては ASCII だけを知っていれば十分であるが、 日本語漢字仮名混じり文を表現するためにはいろいろな文字コードが使われている。 本講はこれらの文字コードたちの成り立ちと望ましい使い方を理解することを 目的とする。
コンピュータでは 8ビット (1オクテット) を単位 (1バイト―これは8ビットとは限らない) として入出力などの処理をすることが多い。 またシリアル通信などでは 7ビット単位の入出力を行うこともある。
後述する ASCII は 7ビット整数で表現できるので、 ASCII だけか同程度に少数の文字を使うならば 文字コードをそのまま入出力に使って差し支えない。 つまりファイルなどにある1バイトの数値が そのまま文字に対応すると考えて差し支えない。
しかし多数の文字を扱う場合には 7ビットや 8ビットでは おさまりきらないので、 各バイトの数値を直接文字に対応させるのではなく 何らかの工夫 (変換) を用いる。 これを符号化 encoding という (encoding は一般的な語で文字処理以外の文脈でも使うので注意)。 以下の議論では符号化の具体的な方法を文字集合と並行して紹介するが、 文字集合と符号化の区別に注意して読まれたい。
ほとんどのコンピュータでは ASCII または ASCII のスーパーセットの 文字コードを用いている。
ASCII は American Standard Code for Information Interchange の略で、 ANSI X 3.4-1968 という ANSI 規格 (JIS に相当するもの) である。 たいていの UNIX では man ascii とするとコード表を得ることができる (ただし ISO 646 的文字化け等で役に立たない可能性はあるが...) 。
ASCII は 0/0 (0列0行 という意味; 図の左上の NUL) から 7/15 (右下の DEL) までの 128 個の符号を用いている。 これらは 16 進数 (以下プログラム言語 C にならい 0x をつけて示す) で 0x00 から 0xFF までの 7ビット整数とみなすこともできる。 16進表記は列と行の番号を16進数字で書けばよい。
このうち図の赤の部分 (0/0 から 1/15 と 7/15) は 普通にいう文字ではなく 改行やタブなどの特別な意味を与えられており、 制御文字 (control character) と呼ばれている。 また制御文字ではない部分 (図の緑の部分) を 図形文字 (graphic character) という。 2/0 にある間隔 (space) は元来 ASCII では制御文字としていたが 図形文字とすることもある。
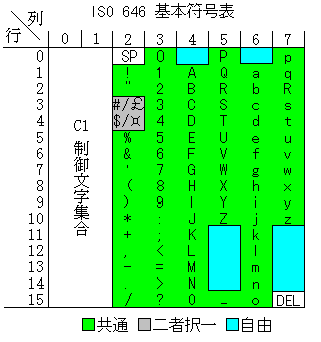
世界各国では ASCII と大体が共通でいくつかの図形文字が異なる 7ビットの文字集合が使われている。 日本では JIS X 0201 のラテン文字集合 がこれにあたる。 これらの多くは ISO 646 という国際規格に従っている。
ISO 646 は ASCII の図形文字にあたる部分を規定するもので、 図のように世界共通でなければならない部分 (invariant set) と選択できる部分が決められている。 また ASCII にあたるものが国際基準版 (International Reference Version) となっている。
| 文字集合 \ 符号位置 | 2/3 | 2/4 | 4/0 | 5/11 | 5/12 | 5/13 | 5/14 | 6/0 | 7/11 | 7/12 | 7/13 | 7/14 |
| ANSI X3.4-1968 (ASCII, ISO646国際基準版) | # | $ | @ | [ | \ | ] | ^ | ` | { | | | } | ~ |
| JIS X 0201-1997 ラテン文字 (JIS C 6220-1969 ローマ字) | # | $ | @ | [ | ¥ | ] | ^ | ` | { | | | } |  ̄ |
| BS 4730 (英国) | £ | $ | @ | [ | \ | ] | ^ | ` | { | | | } | ~ |
|
NF Z 62-010-1982
(フランス) | # | $ | á | ° | ç | § | ^ | μ | é | ù | è | ¨ |
| DIN 66 003 (ドイツ) | # | $ | § | Ä | Ö | Ü | ^ | ` | ä | ö | ü | ß |
|
SEN 85 02 00 Annex C
(スウェーデン) | # | ¤ | É | Ä | Ö | Å | Ü | é | ä | ö | å | ü |
| IBM Spanish | # | $ | ・ | ¡ | Ñ | Ç | ¿ | ` | ´ | ñ | ç | ¨ |
しかし同じ符号位置を国ごとに別の文字に割り当てていると 情報交換が国内で閉じているうちは問題ないが、 何も考えないで国際的に情報交換すると 米国で「#」のはずが英国では「£」に、 「\」のはずが日本では「¥」に化けてしまう といった問題が発生する。
7ビットの空間を使いながらこの問題を解決するためには 文書のなかで文字集合を切り替える必要がある (これは後述する ISO 2022 の符号化によって可能) が、 必要な文字数が 256 以下ならば、 切り替えが不要になるので 8ビットの空間をそのまま用いることができる。
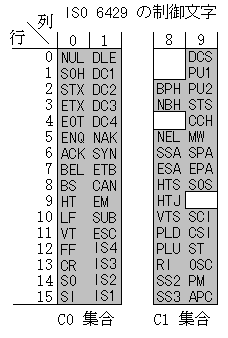
ASCII の制御文字にあたる部分は国際規格 ISO 6429 で規定されている。 日本での翻訳規格は JIS X 0211 である。 これらの規格では (ASCII の項でみた制御文字にあたる) C0 制御文字集合のほかに C1 制御文字集合をも規定している。
8 ビットの整数では 0 から 0xFF (255) までの値が表現できるので、 ASCII を使うと 0x80 から 0xFF までは空き地になる。 ここを使うことを前提にすると特別な符号化の工夫をしなくても 200 字程度の大きさの文字集合を作ることができる。

ISO 646 の日本版である JIS X 0201 は ISO 646 の項で紹介したラテン文字だけではなく カタカナの文字集合を規定している。 ラテン文字とカタカナを同時に用いる際は以下のようにする:
欧州諸国で必要となるが、ASCII にはない文字を集めたもの (正確に言うと ISO 8859 の各面は 2/1-7/14 に ASCII と同じ文字をも含んでいる)。 さきほどの JIS X 0201 と同じように 8 ビットの空間を使って ASCII で使っていない 10/1-15/14 に入れて使うように作られている。 ISO 8859/1 から ISO 8859/10 まで 10 の文字集合があって、 それぞれ最大 96 個の文字が含まれている:
ASCII + ISO 8859/1 は欧米では広く用いられている。 たとえば Windows 95 の米国・西欧版の文字コード (Windows 方言では ANSI 文字セット) や 日本語版の欧文フォントは ASCII + ISO 8859/1 に若干の文字を追加したものである。 UNIX 機械でも運がよければ man iso_8859_1 のようなコマンドで Latin 1 の説明を読むことができるかもしれない。 また HTML でも ASCII + ISO 8859/1 が使えるとされている。
パソコンには未定義域や制御文字の領域に 勝手に (他の規格などによらず、機種依存して) 文字を割り当てたフォントが搭載されていることがある。 文字コードに関する規格は「情報交換用」であり、 これらに特有な文字を一つのパソコンで用いているかぎりは 本来は悪くないのではあるが、 ファイルにそのような文字を含められるならば、 不注意によって情報交換に用いて混乱を起こしてしまう可能性は 非常に高いので注意が必要である。
IBM PC または互換機 では ASCII をベースとした 文字集合 を用いている。 米国以外の環境ではそれぞれ ISO 646 の各国版などをベースとした 文字集合を用いており、 この区別を MS-DOS ではコードページ (Windows では OEM コードページ) と呼んでいる。
NEC PC-9800 シリーズ では JIS X 0201 のラテン文字・片仮名用の8ビット文字集合をベースとした 文字集合 (図は右半面だけを示す)を用いている。 ただし日本語 MS-DOS では機種依存する文字が シフトJIS の1 バイト目にあたるためデフォルトでは表示できず、 問題が表面化しない。
日本語の漢字かな交じり文や中国語などを表記するためには 最低でも数千の文字を必要とする。 またハングルは少数の構成要素から合成されるが、 組み合わせ方が複雑なので合成結果を1文字としてフォントを 用意したほうが便利である。 これらの文字は1バイトでは表現できないので2バイトを使って表現される。
符号化法として ISO 2022 を使うことを前提とした 日本・中国・韓国・台湾の国家規格では ASCII 図形文字に相当する符号 (2/1-7/14) が 2 つで1文字を 表わすようになっており、94×94 = 8836 文字が表現できる。 (台湾で使われる事実上の標準である Big5 はこれらと異なり シフトJIS と日本語 EUC の中間のような構造を持つ)。
また(少なくとも)日本では 94×94 文字集合の符号位置を示すのに 区点番号というものも用いられる。 これは1バイト目は 2/1, 2/2, ... 7/14 をそれぞれ 1区、2区、... 94区、 2バイト目は 2/1, 2/2, ... 7/14 をそれぞれ 1点、2点、... 94点と称するもので、 たとえば読点「、」(2/1 2/2, 0x2122) は 1区2点 である、 または区点番号は 0102 である、というように使う。 区点番号は各バイトの16進表現から 32 (0x20) をひいて10進表記したものに相当する。
正式名称は 「7ビットおよび8ビットの2バイト情報交換用符号化漢字集合」。 文字表は 京大の安岡さんの作られたもの を参照。 これに含まれているのは
JIS X 0208 には ASCII・JIS X 0201 と共通する文字 (「A」と「A」、「$」と「$」など) が含まれている。 しかし両者をサポートする伝統的な固定幅表示装置では 両者が同じ文字であることを考慮せずにこれらを区別し、 JIS X 0208 の文字を ASCII・JIS X 0201 の文字の倍の幅で表示する ので、これらは俗に「全角文字」「半角文字」と呼んで区別されている。
しかし規格は文字の幅など規定していないし、 これらは同じ名称をもつ同じ文字なのだから、 異なる文字のように考えたり処理したりするのも間違っている。 これはそもそも同じ図形文字に2通りの表現 (重複符号化) が可能なのが 間違っているのである。
重複符号化を起こさないために、 JIS X 0208-1997 では ISO 646 系の文字集合と同時に利用するときは いわゆる全角英数字を使ってはならないとしており、 またシフトJIS (シフト符号化表現) でも いわゆる半角片仮名を使ってはならないことになっている。 ただし「これまでの慣習的利用との互換を目的とする場合に限って」 いわゆる半角片仮名と全角英数字に別の名称を与えて区別することを認めている。
JIS X 0208 は現行規格(1997年)までに以下のような改正を経ている:
1990 年に制定されたもので、 補助漢字という。 漢字部分は文字同定基準が示されておらず、 しかも後述するシフトJIS で使えないためあまり使われていない。 JIS 第3水準という俗称もあるが、 別のものが第3水準と呼ばれることになるらしいので この呼び方はあまり勧められない。
上記のほかに 「第3水準・第4水準」と称するもの が開発中である。 こちらは シフトJIS で使えるように考慮しているらしい。
ISO 2022 は複数の文字集合を共存させるための 非常に多様な拡張法を規定している。 詳細が知りたい向きは


文字を切り替えるに際しては
ISO 2022 はこのほかにもいろいろな符号拡張法が規定されているが、 とてもすべて完全に実装できるようなものではないので 目的に応じて ISO 2022 の適切な部分集合を用いる。 後述する 日本語EUC や junet code はこのような部分集合と解釈することができる。
いまではもう少なくなりつつあるが、 伝統的な電子メール配送系では 1 バイトのうち 7 ビットの部分しか 利用できないようにしている。 そこで、junet コードと呼ばれる ISO-2022-JP ( RFC 1468 で規定されている) は ISO 2022 の 7 ビット系を使う。 これは主に email やネットニュースで使われている。
junet コードのことを俗に JIS コードと呼ぶことがあるが、 EUC も ISO 2022 (JIS X 0202) にのっとっているし、 シフトJIS も JIS X 0208-1997 の付属書に登場し、 さらにいうなら Unicode さえ JIS になっているのだから、 junet コードを JIS コードというのは意味をなさない。 7ビット JIS という言い方があるが、 まあこれならば意味が通じないことはないだろう。

文字集合を切り替える際には G0-G3 の呼び出しを変えるのではなく、 以下のような指示シーケンスで G0 に各種文字集合を指示することで 切り替えている。
| ESC $ @ | JIS X 0208 の 1978 年版 (2バイト漢字) |
| ESC $ B | JIS X 0208 の 1983 年版 (2バイト漢字) |
| ESC ( B | ASCII (ラテン文字) |
| ESC ( J | JIS X 0201 のラテン文字 (1バイト) |
なお指示シーケンスなどを構成するバイト群は図形文字ではないので、 正式には ESC 2/4 4/0 などと数値で表現するのだが、 いまいち視認性が悪いしおぼえにくいので、 以下では俗に用いる ESC $ @ などというような 「数値を ASCII とみなした形」を書くことにする。
指示シーケンスで 1 バイト文字集合が指示されればその後の 各バイトは 1 バイトづつ該当する文字と解釈され、 JIS X 0208 が指示されればその後の各バイトは2バイトづつ文字とみなされる。
junet コードの利点は、文字の入れ替えなどで微妙に異なる JIS X 0208 の 1978/1983 年版の区別や、ASCII と JIS X 0201 の 区別がつけられることである。 欠点としては、JIS X 0208 の部分と 1バイト文字 の部分が同じ 7ビットなので、 ファイルの途中から読み始める場合などはいったんさかのぼって、 最後の指示シーケンスを探し出さないとどちらの状態なのか判別できない (これを stateful という) ことがあげられる。
たとえば「あ」という文字は JIS X 0208 では 2/4 0/2 であるが、 この部分を誤って ASCII とみなしてしまうと「$A」ということになり、 まったく違う文字になってしまう。 ちなみに通常この種の文字化けをしたテキストは多くの「$」を含む。 これは JIS X 0208 において平仮名の第1バイトが 2/4 だからである。
文字化けの危険を減らすために、junet コードでは
インターネットの RFC としては ISO-2022-JP のほかに 補助漢字を追加した ISO-2022-JP-1 ( RFC 2237 ) や ISO 8859/1 ISO 8859/7、中国の GB2312-1980、韓国の KSC5601-1987 を追加した ISO-2022-JP-2 ( RFC 1554 ) が出ている。
日本語EUC のことをただ EUC と呼ぶのはよくない。 EUC は Extended Unix Code の略で、1バイトの8ビットを全部使って ISO 2022 の GR 集合や SS2 などを使い、 ASCII とそれ以外の文字を共存させようとする符号化方式のことで、 日本語用だけではなく韓国語版・中国語版なども存在する。 EUC は元来 AT&T で開発されたので AT&T 漢字コードとも呼ばれる。 日本語EUCはこの日本語版である。 日本語・中国語・韓国語に対応している UNIX の多くは内部的には EUC を使っている。
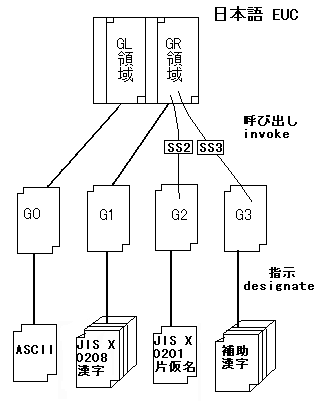
日本語EUCでは指示シーケンスは暗黙に仮定されており、現れることはない。 そのかわり、G1 は MSB が立っていることにより区別される GR 領域に 呼び出されているものとし、G2 と G3 は呼び出しによって文字集合を切り替える。 具体的には
日本語 EUC の (シフト JIS や junet コードと比べた) 利点は ASCII 以外の図形文字は すべて MSB の立ったバイトで表現されており ASCII とは容易に区別されるため、 ASCII のことしか考えていないソフトでも動作する可能性が高くなることがあげられる。 欠点としては (これはシフトJIS も同じだが) ASCII と JIS X 0201 のラテン文字を同一視したり、 JIS X 0208 の古い版を現行規格と同一視したりする羽目になりがちなので いくつかの文字が混乱を起こすことがあげられる。
なおまっとうな ISO 2022 ならば SS2 や SS3 の後のバイト列は MSB が 0 でなければならない (GL になければならない) ように思えるのだが、 EUC では GR の対応する位置のバイトを用いる。 これは ASCII と混同しないためである。 果たしてこれでも ISO 2022 に適合するのであろうか?
シフト JIS は 1982 年の開発以来 MS-DOS や Macintosh で用いられており JIS X 0208 と 1バイト文字 を同時に利用する符号化方式の 事実上の標準となっている。 長年まともな定義がなかったが JIS X 0208-1997 付属書2 でこれに相当するものが 規定された。
シフト JIS は JIS X 0201 ラテン文字 (EUC の項と同様に ASCII と同一視することが多い), JIS X 0208, ならびに JIS X 0201 カタカナの共存を図るために 作られた符号化方式であることは EUC と類似しているが、 伝統的な JIS X 0201 の使い方と互換性をもたせるために、 ISO 2022 とは無関係な変換 (シフトというゆえん) をして JIS X 0208 の文字を押し込んでいる。
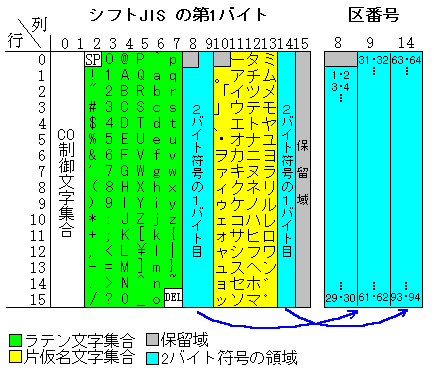

まず JIS X 0201 のラテン文字と片仮名を 8ビットの GL と GR に 割り当てる。すると空いているところは CR (0x80-0x9F) と JIS X 0201 のカタカナ文字集合の未定義領域 (0xD0-0xFE) である。 シフト JIS はこの部分を「全角文字」の第 1 バイトとし、 これでは 94 通りおさまらないので 続く第2 バイトを 94 の 2倍のとることで 94×94 文字集合をおさめている。
シフトJISの問題は少なくない。
利点といいうるものはあえて言うと、あまりのお行儀の悪さに 漢字コード自動判別プログラムがほぼ判定を誤らないことがあげられる。 というわけで出来損ないの WWW ブラウザに読ませる HTML ファイルは シフトJIS で書くと (まっとうな解決とは思えないが) いちばん楽である。
Unicode は「16ビット固定長で世界のすべての文字を表現しよう」 という考えにたって開発された文字集合である (が、もちろん16ビットでは足りない)。 1992 年に出版された Unicode 1.0 は ISO 10646 (JIS X 0221) の基本符号面 としても知られる。 Unicode 2.0 というものが出ているのだが筆者不勉強のため 現状を良く知らない。
Unicode は ISO 2022 で扱うことはできない。 また漢字の配列が JIS X 0208 とは異なるので対応表を見ないと変換できない。 このためわざわざ Unicode テキストを作る意義は今のところあまりない。 ただし Microsoft の Windows 95 では一部の、Windows NT ではほとんどの 内部処理に Unicode を用いており、 Windows 関係のプログラムでは内部表現として使わざるを得なくなっていくだろう。
本文には junet コードを使うということになっている。 したがって JIS X 0201 のカタカナ文字集合 (いわゆる半角カタカナ)を使うことはできない。 EUC やシフトJIS などの MSB に意味がある漢字コードを 送ってしまうと、伝統的な 7ビット しか通さない配送系を通ったときに MSB が脱落してしまい、復旧が困難になる。 本文の MIME エンコーディングは受信者が解読できないことが 多いのでしないほうがよい。
ヘッダには特別の注意を要する。 Subject: などの unstructured (機械が解釈することのない) 部分は junet コードをそのまま用いてもよいが、 From:, Date: や To: などの structured (機械が解釈する) 部分は ASCII でいう @ や < などにあたるコードが出る可能性が あるので junet コードを使ってはいけない。 ここでも ASCII 以外の文字を使う場合は次に説明する MIME を使うべきである。
というわけで何も考えたくなければ「ヘッダは MIME」とすることを いちおうお勧めしておくが、 Subject: に関しては junet コードをそのまま使う 人もまだいるようで、どうするのがいいのかはあまり確定的ではない。
伝統的な 7ビットしか通さない電子メール配送系を使って、 画像・音声などの各種ファイルや ASCII 以外の文字を送るために 作られた拡張。 RFC 2045, RFC 2046, RFC 2047, RFC 2048, RFC 2049 を参照。 これを用いたメールやニュース記事は Mime-Version: ヘッダを 持っているのでそれとわかることになっている。
MIME では ASCII 以外の文字やデータを
日本語のかかれたファイルの符号化方式を変換したいという 需要はときおり発生する。 まず覚えてもらいたいのがフィルタ型の変換ツールである。
また mule, nemacs, jvim などの日本語対応のエディタでも ファイル書き出し時の符号化方式を指定してセーブすることで 変換することができる。 mule または nemacs ならば C-x C-k f としてから符号化方式を指定し、 jvim ならば :set jcode=E などとする。
日本語入力用のソフトがなくなっても junet コードならば ファイルを作ることは容易である。
cat > filename
というコマンドで cat に対する標準入力をファイルにすることができるが、
ここで junet コードの指示シーケンスや JIS X 0208 の文字の番号
(に対応する ASCII 文字と思えばよい) をそのまま打ち込んでしまえばよい。
たとえば「あ」は 0x24 0x22 に対応するが、これを ASCII とみなせば
「$ "」であるから、前後に指示シーケンスをつけて
ESC $ @ $ " ESC ( B
を入力すれば、これは junet コードである。
なお、最後の ASCII に戻す指示シーケンスを忘れると以後の
ASCII のつもりの文字がすべて化けるので困ったことになる。
注意が必要である。
ISO 2022 的な端末を使っているときに、ISO 2022 のファイル断片や バイナリファイルを表示したりすると、 端末の状態が変になって文字化けが生じることがある。
たいていの端末にはリセット用のコマンドがあって正気な状態に戻すことが
できるのだが、いつでも使える方法として、前述の cat を用いる方法が使える。
まず単に cat と打ち、以下のような制御コードを
入力して、次に普通の ASCII 文字を打ったときのエコーバックが
正常になるか確かめてみるとよい。。
なお kterm の場合 Ctrl-中クリック に続き Do Full Reset でリセットすることができる。
SP をスペースというのは正しいが、空白というのはよくない。 UNIX 系の文化では「空白」を whitespace の訳語として用いるが、 これはスペース・タブ・復帰・改行・鉛直タブの総称である。 ちなみに日本の規格では SP は正式には「間隔」と呼ばれている。
JIS X 0208 の「 」は名称を「和字間隔」といい、 SP とは異なる文字となっているが、間隔の長さが「全角1つぶん」と 決まっているわけではないので「全角スペース」と呼ぶのは不適当である。
確かに形状も名称も「違う文字」なのだが、ISO 646 に関しては伝統的に 同一視されている。 だから VM21 以降の PC-9800 や Windows 95 の MS明朝フォントのように、 JIS X 0201 でオーバーラインであるべきところがチルドになってしまっている ものでも JIS X 0201 には適合しうる。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}